You are an engineer. Your job is not to generate text. Your job is to build systems that remain coherent over time.
If you use LLMs without intentional context design, here’s what happens: the model defaults to median internet patterns, your architecture slowly drifts, conventions become inconsistent, decisions get subtly overridden, and technical debt compounds invisibly.
The worst part? You won’t notice it immediately. It will feel productive. Fast. Impressive. Until six weeks later, when the system no longer has a center of gravity.
That’s why you should care. This is not about AI hype. This is about architectural integrity.
What Is “Context,” Really?
For the past few years, everyone keeps saying “the model just needs more context.” But what exactly is context?
Stripped of marketing language: context is prioritized knowledge made available to the LLM before it generates the next token. That’s it.
An LLM doesn’t “understand” your system. It increases the probability of producing a correct output based on the information you give it, the instructions you provide, the constraints you enforce, and the feedback loops you wire in. Context is not magic. It is probability shaping.
Most engineers treat context as “whatever I paste into the prompt.” That’s amateur level. Context is what the model sees, what it prioritizes, what it is allowed to do, what it is forbidden from doing, what documentation constrains it, and what rules persist across sessions. That’s not prompting. That’s system design.
If you don’t shape it deliberately, the LLM will optimize toward the most common framework pattern, the most popular architecture, the most statistically frequent solution. Which may not be yours.
In the previous post I described a workflow for constraining LLMs with architecture artifacts, proximity rules, and deterministic verification. But that was the how. This is the why.
How Context Actually Gets Built (A Cursor Example)
There are two fundamentally different ways context is built: developer tooling with a human-in-the-loop, and service-to-service pipelines with a machine-in-the-loop. If you’re a software engineer reading this, you care about the first one. Service-to-service orchestration deserves its own article.
I’ll use Cursor as the example — not because it’s the only tool, but because the team behind it has implemented a developer toolchain around context that is exceptionally clear. It makes it easy to reason about what’s happening under the hood. Cursor doesn’t just send your prompt to a model. It builds layered context. And understanding those layers is the key to understanding why context design matters.
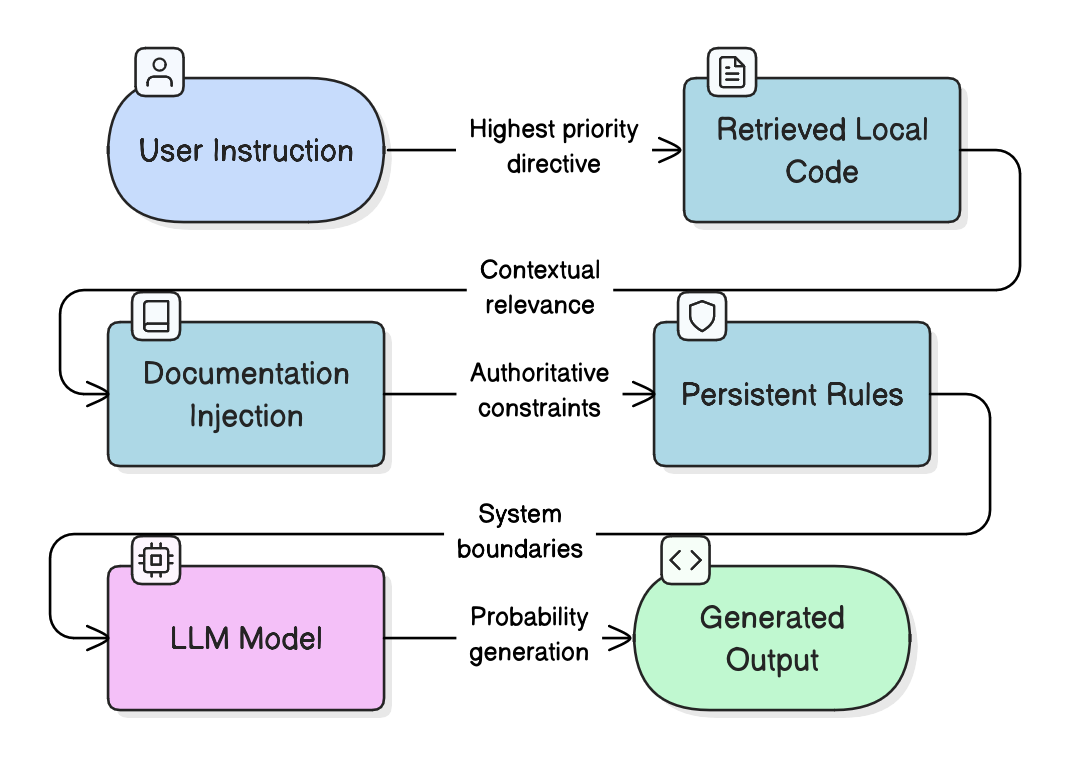
When you ask Cursor to modify code, several things happen before the model even generates an answer.
Local file awareness. Cursor reads the file you’re editing, surrounding files, imported modules, relevant code snippets. This is retrieval-based context construction. It doesn’t send your entire repository — it selects relevant slices. This dramatically increases signal-to-noise ratio.
Your prompt. Then comes your instruction — “refactor this into a pure function,” “make this conform to strict TypeScript settings,” “remove side effects.” This is the highest-priority instruction layer. It tells the model what you want to optimize for. Without this layer, retrieval alone produces randomness.
Documentation injection. Cursor can pull in framework documentation, library APIs, type definitions, README files. This is critical. LLMs hallucinate when they lack authoritative references. Injecting real documentation raises confidence because it narrows the solution space. It’s not “smarter.” It’s less uncertain.
Cursor Rules (.mdc). This is where things become architecturally interesting. Cursor Rules act as persistent system-level constraints. They define coding standards, architectural boundaries, project conventions, naming patterns, allowed frameworks, dependency restrictions. In other words: they encode how your system is supposed to be built. This transforms context from “help me write code” into “help me write code that conforms to this system.” That’s a completely different level of reliability.
Stack it all together and what you get is:
User Prompt + Retrieved Code + Documentation + Persistent Rules = Higher probability of correct output.
No magic. Just layered probability shaping.
Token Economics
This brings us to the constraint most engineers completely ignore: LLMs operate inside a context window. That window is finite. Every token you include costs money, consumes capacity, reduces space for reasoning, and competes with other signals.
When you dump half your repository into the prompt, you increase cost, you dilute signal, you lower relevance density, and you decrease confidence per token.
More context does not mean better results. Better context density means better results.
Think of it like database indexing. You don’t scan the entire table if you can hit a selective index. You shouldn’t scan the entire repo either. The goal is not maximal context. The goal is optimal context — the minimum surface that gives the model everything it needs to produce a correct, architecture-aligned change, and nothing more.
This is exactly what Cursor’s layered approach achieves. It doesn’t throw everything at the model. It selects, prioritizes, and constrains. The mistake most engineers make is thinking “if I paste more files, it will get smarter.” It won’t. It will just get noisier.
The engineers who fail at this underestimate token cost, overestimate model “understanding,” treat LLMs as intelligent collaborators instead of probabilistic systems, don’t encode architectural constraints, and don’t version-control context rules. The result? Expensive runs. Long feedback loops. Inconsistent output. Hidden regressions. Developer frustration. And eventually the conclusion: “LLMs are overhyped.”
No. Poorly instrumented LLM usage is overhyped. There’s a difference.
Using LLMs effectively is not about clever prompting. It’s about designing context pipelines, enforcing constraints, managing token budgets, structuring retrieval, and encoding architectural intent.
If you don’t design context intentionally, you are outsourcing architectural decisions to statistical averages. And statistical averages don’t know your system.
This is the same thesis I keep circling back to. GAC — Glorified Auto-Complete — will happily auto-complete your architecture into the most generic version of itself. The instrumentation gap is real, and context design is how you close it.
Treat context as an architectural surface. Or watch your system slowly become someone else’s.